¿De dónde obtenemos datos biológicos?¶
Autoras: M. Nayeli Luis-Vargas y Marisol Navarro
Experimentos¶
Cuando llevamos a cabo una investigación que involucra el estudio de DNA, seguimos un protocolo de biología molecular para que al final de todo el proceso podamos obtener un archivo con las secuencias de nuestra muestra. En general, los pasos a seguir son:
Extracción de DNA de nuestras muestras
Secuenciación mediante la plataforma de nuestra preferencia.
En algunos casos, se requiere un paso de amplificación, como en los estudios de metabarcoding. Para más información puedes revisar la sección de Métodos de biología molecular del Manual de biología molecular para no biólogos.
Toma en cuenta que
Los estudios con DNA pueden ser de:
Genómica: Que es el estudio del conjunto completo de genes que hay en un organismo.
Metagenómica: Que es el estudio de una colección de genomas de una comunidad de organismos. Y es frecuentemente utilizado para el estudio de comunidades microbianas.
Metabarcoding: Este término hace referencia a la identificación de alto rendimiento de especies múltiples, utilizando DNA de origen ambiental, es decir, DNA en muestras de suelo, agua, etc. Con ésta técnica se busca un gen o un fragmento de gen en específico y no el conjunto de todos los genes.
Repositorios de secuencias de DNA, RNA y/o proteínas¶
El International Nucleotide Sequence Database Collaboration (INSDC) ha hecho varios esfuerzos por mantener las secuencias de DNA originales de diversas investigaciones. Los miembors de éstas organizaciones son:
NCBI: National Center for Biotechnology Information
EMBL: European Molecular Biology Laboratory
DDBJ: DNA Data Bank of Japan
El INDSC propuso ciertas reglas para almacenar información contenida en DNA. Y quienes cumplen con estas reglas son los siguientes repositorios:
Gene Bank: contiene toda la información de secuencias de DNA anotadas e identificadas.
SRA (Short Read Archive): que contiene mediciones de experimentos de secuenciación de alto rendimiento.
UniProt (Universal Protein Resource): Repositorio de secuencias de proteínas.
Protein Data Bank: Repositorio de información estructural 3D de macromoléculas biológicas.
Más repositorios
Si quieres saber de más sitios donde puedes obtener datos de origen biológico te recomiendo el artículo de Database resources of the National Center for Biotechnology Information (2019) de Sayers y colaboradores.
Obtención de secuencias del NCBI¶
En ésta sección aprenderás a descargar secuencias desde el National Center for Biotechnology Information (NCBI). Te sugerimos llevar a cabo el ejercicio, pues las secuencias que descargues las necesitarás para realizar la Práctica 3:
Descargar secuencias de DNA¶
Entra a la página del NCBI https://www.ncbi.nlm.nih.gov/. Escribe en el buscador el organismo que deseas, en este caso buscaremos el genoma del virus que provocó la pandemia actual. Da click en “buscar”.
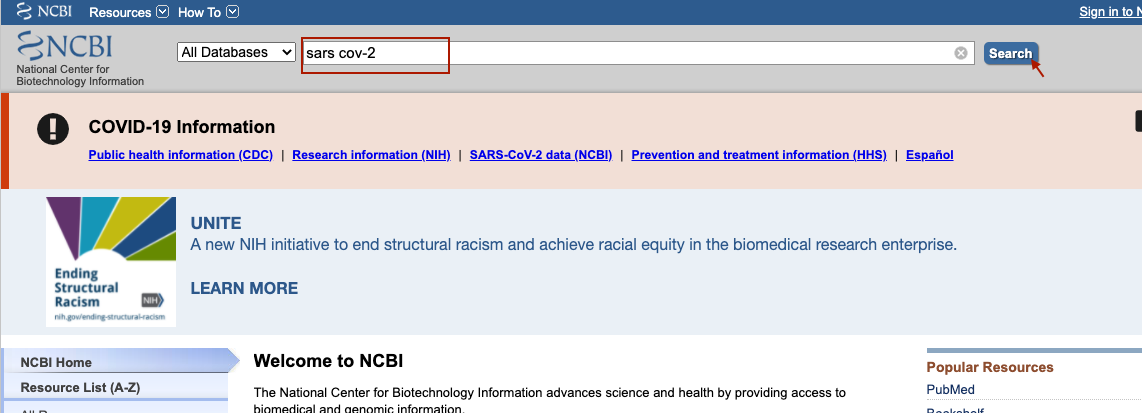
Te redirigirá a otra página con los datos del organismo. Da click en el recuadro que dice “Reference genome”.
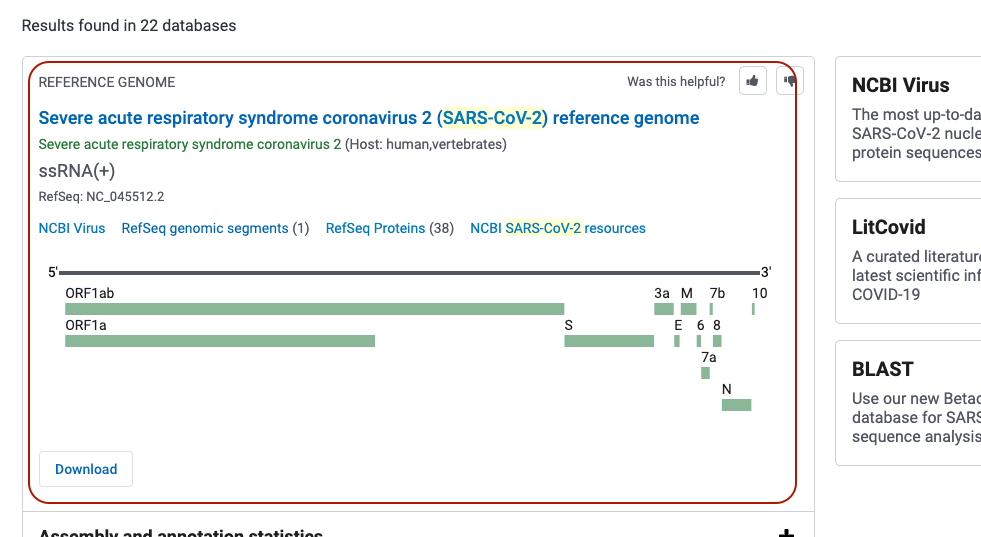
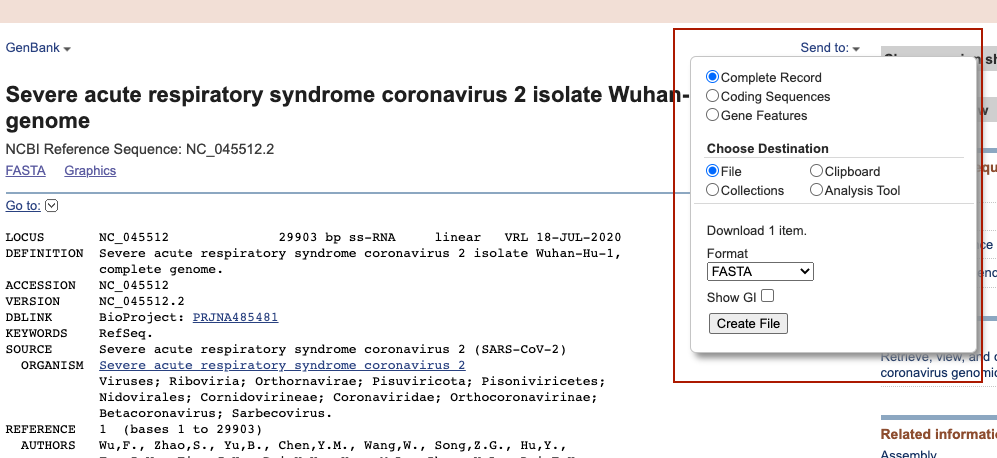
En seguida te redirigirá a una página con un formato de GeneBank (en el siguiente apartado vemos los formatos). Da clcik en “Send to:” y selecciona las opciones “Complete Record” y “File”. Te desplegará un pequeño apartado que dice “Format” primero seleccionaras el que diga
FASTAy darás click en “Create File”. Te descargará un archivo con nombresequence.fasta. Repetirás el proceso para ahroa descargar un archivo con formatoGFF3, tendrás un segundo archivo con nombresequence.GFF3. Renombra los archivossequence.fasta -> sarscov2_genome.fastaysequence.gff3 -> sarscov2_genome.gff3.
Descargar secuencias de proteínas¶
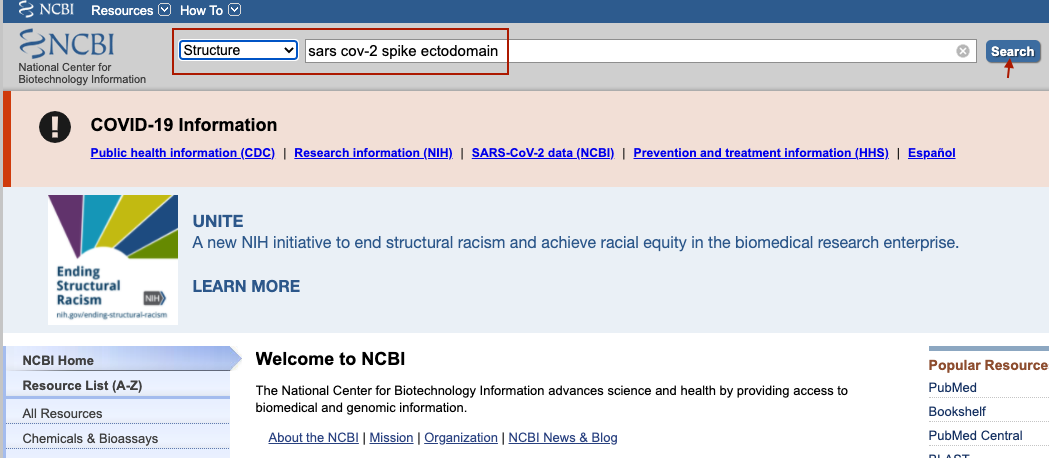
Entra a la página del NCBI https://www.ncbi.nlm.nih.gov/g. Escribe en el buscador la proteína que deseas, en este caso buscaremos una proteína del virus que provocó la pandemia actual (sars cov-2 spike ectodomain). Luego, despliega el menú en donde dice “All Databases” y selecciona “Structure”. Da click en “buscar”.
Da click en la opción 2: Structure of the SARS-CoV-2 spike glycoprotein (closed state)[VIRAL PROTEIN] . Te redirigirá a otro sitio y ahí da click en “Download sequence data”.
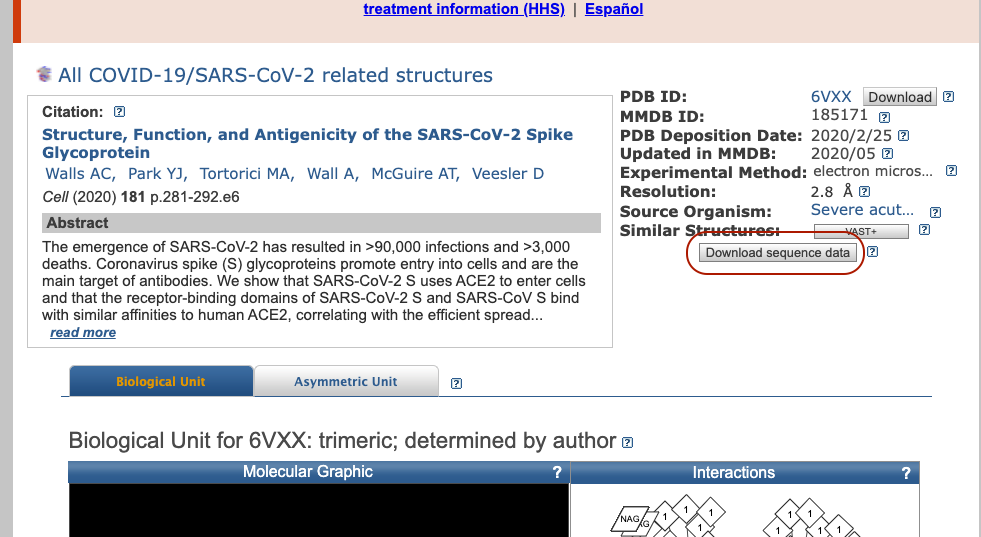
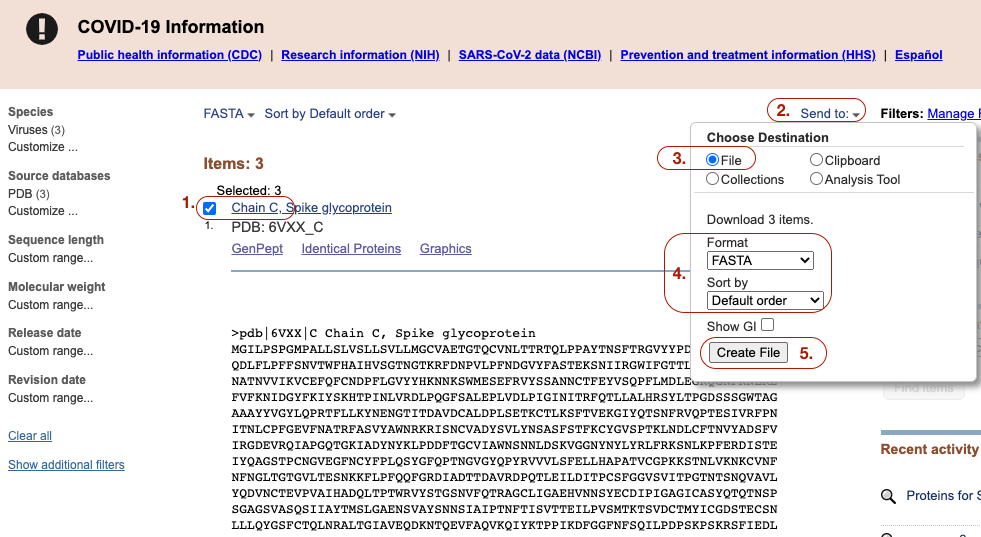
Descargarás las cadenas A, B y C. Para esto:
selecciona la cadena,
da click en “Send to:”,
Selecciona “File”,
seleccciona en archivo
FASTAy “default order” y, por último 4. Click en “create file”.Renombra los archivos que descargaste, el de la cadena A como
splike_a.faa, el de la cadena B comosplike_b.faay el de la cadena C comosplike_c.faa
Atención
Debes seleccionarlas y descargarlas una por una, para que al final tengas tres archivos.